Partie 1 : Premiers pas en SQL
Écrire des requêtes SQL simples et avec jointures
Les bases
Une base de données, c'est quoi ?
Vous pouvez stocker des informations dans des fichiers texte mais très rapidement, suivant l'ampleur de votre projet, cette technologie atteindra ses limites que ce soit en terme de performances ou d'utilisation au quotidien. Si plusieurs personnes souhaitent modifier un fichier texte de données en même temps les erreurs seront inévitables. Il existe une solution pour stocker des informations et pouvoir travailler avec : les bases de données.
Une base de données (database en anglais) est un conteneur dans lequel il est possible de stocker des données de façon structurée. Cette structure permet au programme informatique connectée à celle-ci de faire des recherches complexes.
Un langage standardisé - SQL - est dédié à cette structure et permet aussi bien de faire des recherches mais aussi des modifications ou des suppressions.
Les logiciels permettant de gérer les bases de données sont appelés des systèmes de gestion de bases de données (SGBD). Ils permettent la structuration, le stockage, la mise à jour et la maintenance d'une base de données. Ils sont donc l'interface entre l'utilisateur et la base de données.
Il ne faut donc pas confondre une base de données qui est un conteneur et le SGBD qui est un logiciel de gestion de bases de données.
Systèmes de gestion de bases de données principaux
- Oracle est un SGBD relationnel (et relationnel-objet dans ses dernières versions) très reconnu pour les applications professionnelles.
- PostgreSQL est un SGBD relationnel et relationnel-objet puissant qui offre une alternative open source aux solutions commerciales comme Oracle ou IBM.
- MySQL est un SGBD relationnel libre (licence GPL et commerciale), simple d'accès et très utilisé dans le web.
- MariaDB, fork communautaire de MySQL suite au rachat par Sun (lui-même racheté par Oracle).
- Access est un SGBD relationnel Microsoft, qui offre une interface graphique permettant de concevoir rapidement des applications de petite envergure ou de réaliser des prototypes.
- SQLite est un SGBD relationnel qui présente la particularité de gérer une base dans un fichier unique intégré au programme. SQLite présente l'avantage de n'avoir rien à configurer, rien à maintenir ou à administrer. En contrepartie, certaines fonctionnalités sont absentes, comme la gestion des utilisateurs.
Bases de données relationnelles
Ces SGBD sont des systèmes de gestion de bases de données relationnels. Une base de données relationnelle est une base de données où l'information est organisée dans des tableaux à double entrée appelées tables, comme ici la table serials qui contient les informations concernant les serials (des arcs narratifs) de Dr Who :
| id | season_id | story | serial | title | production_code |
|---|---|---|---|---|---|
| 214 | 31 | 198a | 12 | The Stolen Earth | 4.12 |
| 213 | 31 | 197 | 11 | Turn Left | 4.11 |
| 212 | 31 | 196 | 10 | Midnight | 4.8 |
| 211 | 31 | 195b | 9 | Forest of the Dead | 4.10 |
| 210 | 31 | 195a | 8 | Silence in the Library | 4.9 |
| 209 | 31 | 194 | 7 | The Unicorn and the Wasp | 4.7 |
Les colonnes de ces tables sont appelées attributs. Ici ce sont id, season_id, story, serial, title, production_code. Les lignes sont elles appelées enregistrements.
Selon le modèle relationnel, plusieurs tables peuvent être connectées par les valeurs qu'elles contiennent. Les liens existants entre les informations sont stockés dans les champs des enregistrements sous forme de clé primaire et clé étrangère.
La clé primaire d'un enregistrement est une valeur unique dans une table qui caractérise l'enregistrement. Ici le champ id est une clé primaire. La clé étrangère référence une clé primaire dans une autre table. Dans cet exemple, on a la clé season_id.
Le schéma de ces relations fait apparaître les entités (tables dans la base de données), leurs attributs et relations.
Par exemple, le schéma plus complet de notre base qui contient la table serials ressemble à ceci :
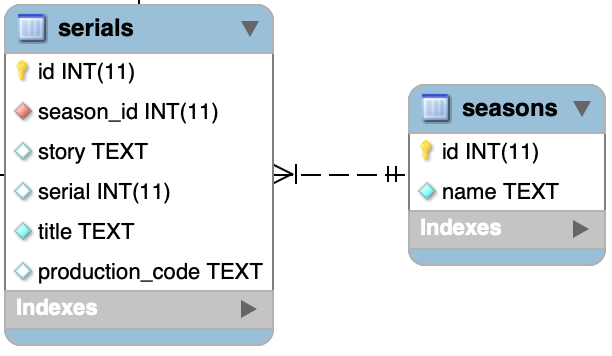
On retrouve notre table serials avec ses attributs id (clé primaire), season_id (clé étrangère), story, serial, title, production_code et la table seasons avec ses attributs id (clé primaire) et name.
La clé étrangère serials.season_id dans la table serials référence la clé primaire seasons.id dans la table seasons. Ce lien permet de faire la correspondance entre un serial et sa saison.
Le modèle relationnel n'est pas le seul modèle possible pour représenter des données. Depuis les années 2010, la famille de SGBD NoSQL (pour not only SQL) propose des SGBD orientés agrégats ou encore graphes.
Premiers pas avec PhpMyAdmin
Mise en route du serveur web
Démarrez le serveur Wamp puis démarrez les services. Vous pouvez ensuite ouvrir PhpMyAdmin dans votre navigateur à l'adresse http://localhost/phpmyadmin. Vous devriez obtenir une page semblable à celle-ci :
Importer une base de données
Vous allez importer une base de données contenant les informations de la série Doctor Who depuis 1963. Commencez par télécharger la base de données au format SQL à cette adresse : http://chloecabot.com/lpmn/BDD/doctorwho.sql et enregistrez là sur votre disque.
Les fichiers SQL sont consultables dans un éditeur de texte, vous pouvez l'ouvrir pour regarder son contenu (It's bigger in the inside !).
Pour importer cette base dans votre système MySQL, cliquez sur l'onglet "Importer" en haut dans PhpMyAdmin. Sélectionnez votre fichier SQL à importer, décochez "Enable foreign key checks" et validez. Vous devriez voir apparaître une nouvelle base de données doctorwho dans le menu à gauche.
Consulter la structure de la base de données
PhpMyAdmin permet de consulter le schéma des données.- Cliquez sur le nom de la base doctorwho dans le menu à gauche
- Vous voyez apparaître la liste des tables de la base. Combien de tables contient-elle ? Combien d'enregistrements possède la base ?
6 tables, 1591 enregistrements.
- Dans la liste à gauche, cliquez sur la table
episodes. Qu'obtenez-vous ?Le contenu de la table episodes, les 25 premières lignes sur un total de 849.
- Allez dans l'onglet Structure. Combien d'attributs sont présents dans la table
episodes?11 attributs
- Quelle est la clé primaire de la table
episodes?id
Premières requêtes
Dans PhpMyAdmin, sélectionnez toujours la base doctorwho puis la table episodes et allez dans l'onglet SQL.

La zone de texte est pré-remplie avec une requête de la forme :
SELECT les attributs à afficher
FROM la table dans laquelle on cherche
WHERE les critères de recherche, séparés par OR ou AND par exemple
Par exemple, la requête :
SELECT title
FROM episodes
WHERE id=1;
affichera tous les titres des épisodes dont l'identifiant est 1.
- À votre avis, que va t'on obtenir avec la requête pré-remplie ? Validez la requête pour vérifier votre réponse.
On obtient la liste de tous les épisodes avec tous leurs attributs. Le caractère * signifie tout et where 1 n'applique aucune contrainte.
- Modifiez la requête pour afficher seulement le titre de tous les épisodes.
SELECT title FROM `episodes`; - Affichez tous les attributs de l'épisode dont l'identifiant est 741.
SELECT * FROM `episodes` WHERE id=741; - Affichez seulement le titre de l'épisode dont l'identifiant est égal à 741.
SELECT title FROM `episodes` WHERE id=741; - Affichez tous les attributs des épisodes qui durent 45 minutes.
SELECT * FROM `episodes` WHERE runtime="45:00"; - Affichez le titre et la date de diffusion des épisodes "manquants".
SELECT title, original_air_date FROM `episodes` WHERE missing=1;
Note : Et oui, lors de la première série de 1963 à 1989, autres temps, autres mœurs, la BBC a effacé des bandes de la série. Certains épisodes sont donc perdus ! - Affichez tous les attributs des épisodes dont l'identifiant est supérieur à 800.
SELECT * FROM `episodes` WHERE id>800; - Affichez tous les attributs des épisodes dont le score d'appréciation est supérieur ou égal à 88.
SELECT * FROM `episodes` WHERE appreciation_index>=88; - Le langage SQL reconnaît les connecteurs logiques, comme par exemple OR et AND. On peut notamment les utiliser dans la clause WHERE. Affichez les épisodes dont l'identifiant est 1 ou 10.
SELECT * FROM `episodes` WHERE id=1 OR id=10; - Affichez les épisodes dont le
serial_idest compris entre 213 et 217.SELECT * FROM `episodes` WHERE serial_id >= 213 AND serial_id <= 217; - Affichez les épisodes de la story 8 dont le score d'appréciation est supérieur à 50.
SELECT * FROM `episodes` WHERE story=8 AND appreciation_index>50;
Exploiter les données
Le langage SQL propose de nombreuses (très nombreuses) instructions et fonctions pour exploiter les données d'une base. Vous pouvez bien sûr toutes les retrouver dans la doc. On va en voir quelques unes seulement (et ce sera déjà beaucoup). Allons-y !
Éliminer les doublons
L’utilisation de la commande SELECT peut potentiellement afficher des lignes en doubles. Testez par exemple la requête SELECT episode_order FROM `episodes`. Pour éviter des redondances dans les résultats il faut simplement ajouter DISTINCT après le mot SELECT : SELECT DISTINCT episode_order FROM `episodes`
- Affichez tous les nombres d'audience distincts.
SELECT DISTINCT uk_viewers_mm from `episodes`; - Affichez toutes les durées distinctes d'épisodes dont l'identifiant est supérieur à 700.
SELECT DISTINCT runtime from `episodes` WHERE id>700;
Trier et limiter les résultats
Pour ordonner les résultats, on utilise ORDER BY suivi du nom de la colonne. Par défaut, les résultats sont triés dans l'ordre croissant. On peut modifier ce comportement en utilisant ASC et DESC. Par exemple : SELECT * FROM `episodes` ORDER BY id DESC;
Il est possible de limiter les résultats obtenus, par exemple pour n'afficher que les X premiers. On utilise pour cela la clause LIMIT. Par exemple : SELECT * FROM `episodes` ORDER BY id DESC LIMIT 10;
- Affichez les épisodes par ordre d'appréciation décroissante
SELECT * FROM `episodes` ORDER BY appreciation_index DESC; - Affichez les épisodes en triant les titres par ordre alphabétique croissant (il n'y a pas de piège)
SELECT * FROM `episodes` ORDER BY title; - Affichez les épisodes d'une durée de 45 minutes par ordre d'appréciation et audience décroissantes
SELECT * FROM `episodes` WHERE runtime="45:00" ORDER BY appreciation_index DESC, uk_viewers_mm DESC; - Affichez les 20 épisodes les moins appréciés.
SELECT * FROM `episodes` ORDER BY appreciation_index ASC LIMIT 20; - Affichez les 10 épisodes les plus longs ayant un score d'appréciation d'au moins 60.
SELECT * FROM `episodes` WHERE appreciation_index>=60 ORDER BY runtime DESC LIMIT 10;
Note : Il est de bon ton de toujours trier les résultats lorsqu'on utilise LIMIT. En effet, l'ordre d'apparition des résultats est aléatoire. Si les résultats ne sont pas triés, le résultat d'une requête utilisant LIMIT sont donc aléatoires.
Chercher un valeur dans un champ
Chercher dans un intervalle
On a vu qu'on pouvait spécifier un intervalle en utilisant les opérateurs numériques et AND. MySQL fournit aussi l'opérateur BETWEEN pour sélectionner un intervalle de données dans une requête. Exemple : SELECT * FROM `episodes` WHERE id BETWEEN 1 AND 5.
Chercher dans une liste
L'opérateur IN permet de tester si une valeur est présente dans une liste. Il évite d'utiliser une multitude de OR. Par exemple : SELECT * FROM `episodes` where runtime IN ("45:00", "90:00");
Chercher dans du texte
Pour chercher un motif dans du texte, on peut utiliser l'opérateur LIKE et les wildcards % et _. % remplace plusieurs caractères tandis que _ remplace un seul caractère. Exemple : SELECT * FROM `episodes` WHERE title LIKE "The%"; affichera tous les épisodes dont le titre commence par "The".
- Affichez les 20 épisodes les moins appréciés dont la durée est de 20 à 30 minutes.
SELECT * FROM `episodes` WHERE runtime BETWEEN "20:00" AND "30:00" ORDER BY appreciation_index ASC LIMIT 20; - Affichez les 10 épisodes les plus longs ayant un score d'appréciation compris entre 60 et 80.
SELECT * FROM `episodes` WHERE appreciation_index BETWEEN 60 AND 80 ORDER BY runtime DESC LIMIT 10; - Affichez les épisodes des stories 20, 127, 44,180.
SELECT * FROM `episodes` WHERE story IN (20, 127, 44,180); - Affichez les épisodes diffusés en 2006.
SELECT * FROM `episodes` WHERE original_air_date LIKE "2006%"; - Affichez les épisodes dont le titre contient "Earth".
SELECT * FROM `episodes` WHERE title LIKE "%Earth%";
Manipuler du texte
Longueur d'une chaîne
La fonction LENGTH permet de calculer la longueur d'une chaîne de caractère. Exemple : SELECT title, LENGTH(title) FROM `episodes` WHERE title LIKE "The%";
Récupérer une sous-chaîne
La fonction SUBSTRING permet d'obtenir une partie d'une chaîne de caractères. Elle prend en paramètre jusqu'à 3 valeurs : la chaine à traiter (obligatoire), la position de début de la sous-chaîne à extraire (obligatoire), la longueur de la sous-chaîne à extraire (facultatif, par défaut jusqu'à la fin de la chaîne). Exemples :
SELECT title, SUBSTRING(title, 1, 5) FROM `episodes`; affichera le titre complet puis les 5 premiers caractères du titre des épisodes de la table.
SELECT title, SUBSTRING(title, 10) FROM `episodes`; affichera le titre complet puis la sous-chaîne allant du 10è caractère inclus jusqu'à la fin du titre des épisodes de la table.
Changer la casse des chaînes
Les fonctions UPPER(chaine) et LOWER(chaine) permettent respectivement de mettre tous les caractères en majuscules et en minuscules. Exemple : SELECT title, UPPER(title) FROM `episodes`;
Remplacer des caractères
La fonction REPLACE(chaine, ancien_caractere, nouveaucaractere) permet de remplacer un caractère par un autre dans une chaîne. Exemple : SELECT title, REPLACE(original_air_date, '-', '/') FROM `episodes`;
Concaténer des chaînes
La fonction CONCAT(chaine1, chaine2, ...) additionne toutes les chaînes passées en paramètres. La fonction CONCAT_WS(' ', chaine1, chaine2, ...) additionne toutes les chaînes passées en paramètres en les séparant par la valeur du premier argument. Exemple : SELECT CONCAT_WS(' ', title, original_air_date, runtime) FROM `episodes`;
Et d'autres...
REVERSE permet d'inverser une chaîne, TRIM d'enlever les espaces à droite ou à gauche, STRCMP compare deux chaînes... Je vous épargne :) Vous pouvez toutes les retrouver dans la doc ici : https://dev.mysql.com/doc/refman/8.0/en/string-functions.html
- Affichez les 3 épisodes ayant le plus long titre contenant "Earth" .
SELECT * FROM `episodes` WHERE title LIKE "%Earth%" ORDER BY LENGTH(title) DESC LIMIT 3; - Affichez l'année de diffusion de tous les épisodes.
SELECT original_air_date, SUBSTRING(original_air_date, 1, 4) FROM `episodes`; - Affichez l'année de diffusion de tous les épisodes diffusés à partir de 2000.
SELECT original_air_date, SUBSTRING(original_air_date, 1, 4) FROM `episodes` WHERE SUBSTRING(original_air_date, 1, 4) >= 2000; - Affichez le titre des épisodes en minuscules en remplaçant les espaces par des underscores.
SELECT REPLACE(LOWER(title), ' ', '_') FROM `episodes`; - Affichez une chaîne composée du numéro de la story et du titre des épisodes en minuscules en remplaçant les espaces par des underscores.
SELECT CONCAT_WS('_', story, REPLACE(LOWER(title), ' ', '_')) FROM `episodes`;
Manipuler des nombres
Arrondis
Plusieurs fonctions existent pour arrondir des nombres :
- CEIL(nombre) arrondit au nombre entier supérieur
- FLOOR(nombre) arrondit à l'entier inférieur
- ROUND(nombre, 2) arrondit nombre à deux décimales
Calcul de somme, moyenne, min et max
L’instruction SUM permet de sommer tous les résultats d’une colonne. Exemple : SELECT SUM(SUBSTRING(runtime, 1, 2)) FROM `episodes` va additionner toutes les durées en minutes de tous les épisodes
La fonction AVG fonctionne de la même façon que la fonction SUM mais calcule la moyenne des valeurs à la place de la somme de valeurs. Il en est de même pour la fonction MIN et la fonction MAX.
- Affichez l'appréciation la plus élevée avec MAX
SELECT MAX(appreciation_index) FROM `episodes`; - Affichez la moyenne des scores d'appréciation
SELECT AVG(appreciation_index) FROM `episodes`; - Affichez la moyenne des scores d'appréciation arrondie à deux chiffres après la virgule
SELECT ROUND(AVG(appreciation_index),2) FROM `episodes`; - Affichez la moyenne des scores d'appréciation arrondie à deux chiffres après la virgule des épisodes diffusés avant 2000. Faites la même chose pour les épisodes diffusés après 2000.
SELECT ROUND(AVG(appreciation_index), 2) FROM `episodes` WHERE SUBSTRING(original_air_date, 1, 4) <= 2000; -- Avant 2000 SELECT ROUND(AVG(appreciation_index), 2) FROM `episodes` WHERE SUBSTRING(original_air_date, 1, 4) >= 2000; -- Après 2000
Renommer
Il est possible de renommer les éléments manipulés, de donner des alias, avec le mot-clé AS. Par exemple, dans cette requête : SELECT original_air_date, SUBSTRING(original_air_date, 1, 4) FROM `episodes`, on a une colonne intitulée SUBSTRING(original_air_date, 1, 4). On peut la renommer, comme ceci (testez !) :
SELECT original_air_date, SUBSTRING(original_air_date, 1, 4) AS year FROM `episodes`;
C'est particulièrement utile pour les jointures et les sous-requêtes que l'on verra un peu plus tard.
- Reprenez votre dernière requête qui permettait d'afficher la moyenne des scores d'appréciation arrondie à deux chiffres après la virgule des épisodes diffusés avant 2000 et renommez la colonne en "appreciation_average".
SELECT ROUND(AVG(appreciation_index), 2) AS appreciation_average FROM `episodes` WHERE SUBSTRING(original_air_date, 1, 4) <= 2000
Compter les résultats
La fonction COUNT permet de calculer le nombre de résultats et de l’afficher. Le COUNT se positionne dans la clause SELECT comme ceci : SELECT COUNT(*) FROM `episodes` va compter le nombre d'épisodes de la table.
- Comptez les épisodes diffusés avant 2000. Puis après 2000
SELECT COUNT(*) FROM `episodes` WHERE SUBSTRING(original_air_date, 1, 4) <= 2000 -- Avant SELECT COUNT(*) FROM `episodes WHERE SUBSTRING(original_air_date, 1, 4) <= 2000 -- Après
Regrouper
GROUP BY
Si je vous demande de compter le nombre d'épisodes diffusés par an, comment allez-vous faire ? D'après ce qu'on a vu jusqu'à présent, il faudrait écrire autant de requêtes que d'années ? Non ! SQL permet de regrouper des résultats selon les valeurs d’un attribut. On peut ainsi grouper nos épisodes par story, par année de diffusion etc etc. Pour cela on utilise l'instruction GROUP BY, placée derrière la clause WHERE. Exemple : SELECT story, COUNT(*) FROM episodes GROUP BY story; va afficher le numéro de la story, et le nombre d'épisodes qui la compose.
HAVING
Comment faire pour afficher seulement les stories composés de plus d'1 épisode ? On ne peut pas le faire dans la clause WHERE, elle ne supporte pas les fonctions d'agrégation comme AVG, COUNT etc. Pour cela on utilise la condition HAVING, comme ceci SELECT story, COUNT(*) FROM episodes GROUP BY story HAVING COUNT(*) > 1;. Et voilà, le nombre d'épisodes par story en contenant plus d'1 !
- Affichez le nombre d'épisodes diffusés chaque année
SELECT SUBSTRING(original_air_date, 1, 4), COUNT(*) FROM `episodes` GROUP BY SUBSTRING(original_air_date, 1, 4); SELECT SUBSTRING(original_air_date, 1, 4) AS year, COUNT(*) FROM `episodes` GROUP BY year; -- avec un alias c'est mieux - Affichez l'année, le nombre d'épisodes diffusés et l'audience moyenne des épisodes par année
SELECT SUBSTRING(original_air_date, 1, 4) AS year, COUNT(*), avg(uk_viewers_mm) FROM `episodes` GROUP BY year - Affichez l'année, le nombre d'épisodes diffusés et l'audience moyenne des épisodes par année, uniquement pour les années postérieures à 2005 et ayant eu une audience supérieure à 8.
SELECT SUBSTRING(original_air_date, 1, 4) AS year, COUNT(*), avg(uk_viewers_mm) FROM `episodes` GROUP BY year HAVING year > 2005 AND avg(uk_viewers_mm) > 8 - On peut aussi grouper selon plusieurs valeurs en même temps. Regroupez les épisodes par année et story et affichez l'année, le numéro de la story et le nombre d'épisodes qui la compose
SELECT SUBSTRING(original_air_date, 1, 4) AS year, story, count(*) FROM `episodes` GROUP BY year, story
Pfiou ! Fini pour cette partie. Malheureusement pour vous, vous n'êtes pas un Time Lord donc pas de régénération, on enchaîne avec un nouveau problème.
Jusqu'à maintenant, vous avez travaillé uniquement dans la table episodes. Vous commencez à connaître le titre de tous les épisodes par cœur et ça devient fatiguant... On ne sait même pas quel docteur joue dans quel épisode, ni même à quelle saison l'épisode appartient. En effet, vous l'avez vu au début, les informations concernant les docteurs, les acteurs, les saisons sont stockées dans d'autres tables. Pour y accéder, il va donc falloir combiner les données de plusieurs tables en même temps. Et pour ça on va utiliser les fameuses clés (non pas celle du TARDIS).
Croiser des tables : les jointures
Clés primaires et clés étrangères
Revenons donc sur ces clés dont on a parlé au début du TP.
Les clés primaires sont des valeurs uniques, non nulles qui caractérisent un enregistrement. Elles servent de référence pour établir des liens avec d'autres tables.
Une clé étrangère est un champ dans une table qui fait référence à la clé primaire d'une autre table.
L'utilisation des clés primaires et étrangères permet d'assurer l'intégrité et la cohérence des données. Une table ne pourra faire référence qu'aux données d'une autre table. On les appelle aussi des contraintes.
Dans notre base doctorwho, nous avons 6 tables : actors, doctors, episodes, seasons, serials et serials_doctors. Ces 6 tables possèdent des liens entre elles : un serial fait partie d'une saison, un épisode fait partie d'un serial, un docteur apparaît dans un serial, un acteur joue un docteur.
Ce schéma de notre base fait apparaître ces relations et les clés dans les tables correspondantes :
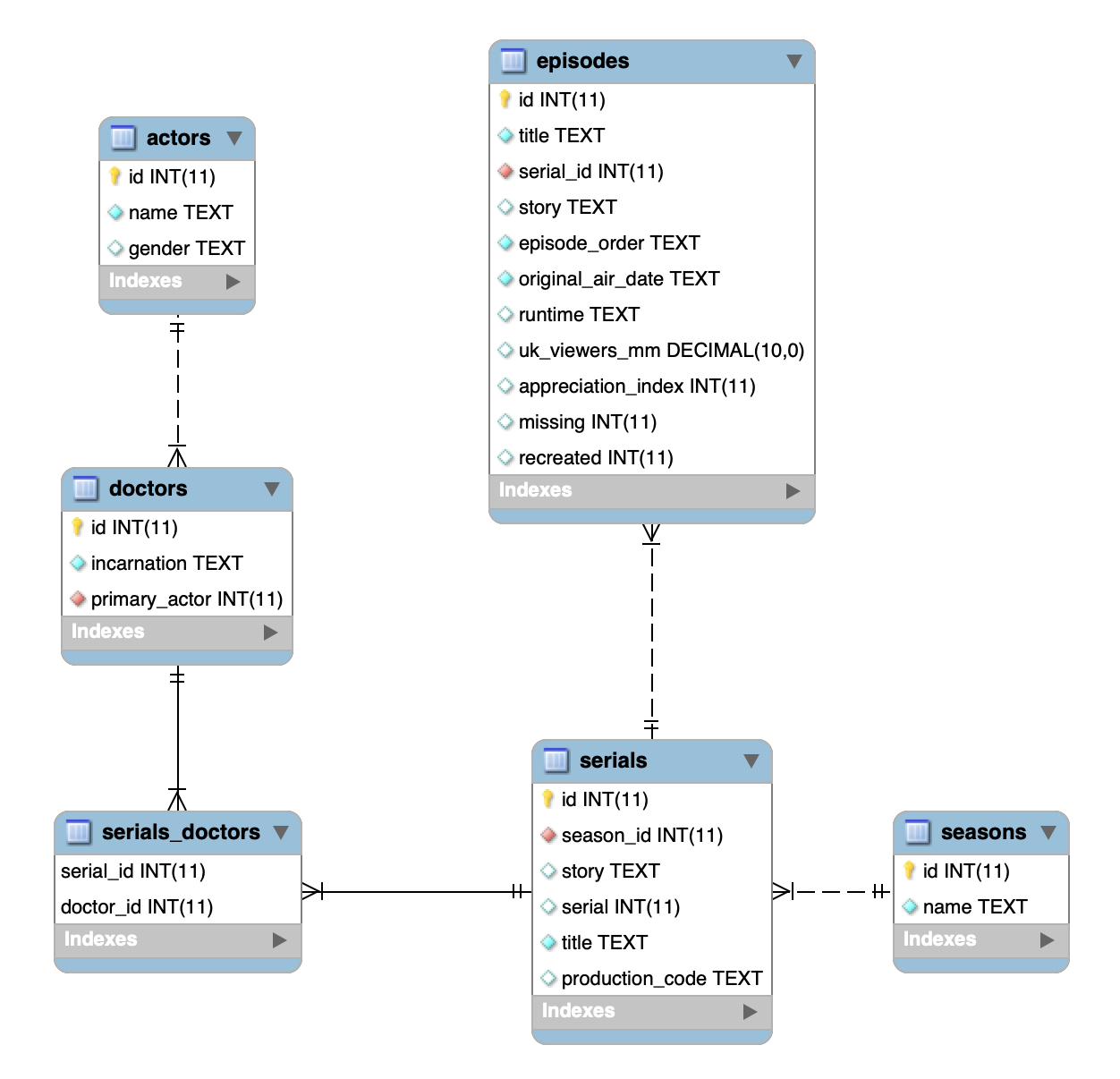
Comme vous voyez, il y a deux types de relations sur ce schéma : des flèches pleines et des flèches en pointillés. En effet, plusieurs types de relations existent :
- Les relations de 1 à 1 et de 1 à n : Un épisode apparaît dans un seul serial, un serial correspond à une saison ou à plusieurs, un acteur joue un seul docteur.
- Les relations de n à n : plusieurs docteurs apparaissent dans plusieurs serials. Plusieurs peuvent même apparaître dans le même épisode (croyez moi sur parole si vous ne connaissez pas la série). Pour les relations de n à n, on a besoin d'une table intermédiaire pour mettre en place la relation. Cette table dans notre schéma est la table
serials_doctors. Elle fait correspondre chaque identifiant de docteur avec le serial dans lequel il apparaît. Vous pouvez l'afficher, vous constaterez les deux colonnes d'identifiants. Tapez cette requête par exemple :SELECT * FROM `serials_doctors` WHERE serial_id = 263et vous verrez que les docteurs 9, 11 et 12 jouent tous les trois dans le serial 263. C'est l'épisode du 50è anniversaire où apparaissent Matt Smith, David Tennant et John Hurt.
Vous vous en doutez, on va pouvoir exploiter ces relations pour relier les données de plusieurs tables et savoir enfin quelle saison de Doctor Who a été la plus appréciée.
Jointures
Pour relier les données de plusieurs tables, on fait ce qu'on appelle des jointures. Voyons donc comment faire une jointure pour obtenir la liste des serials de la saison 1.
Regardez le schéma, dans la table serials on a une clé étrangère season_id qui référence la clé primaire id dans la table seasons.
SELECT *
FROM seasons
INNER JOIN serials
ON seasons.id = serials.season_id
Et on obtient les deux tables avec tous leurs champs combinés !
On peut afficher seulement certains champs bien sûr, là par exemple, la requête affiche le nom de la saison, et tous les champs de la table serials :
SELECT seasons.name, serials.*
FROM seasons
INNER JOIN serials
ON seasons.id = serials.season_id
- Affichez les docteurs et leur acteur respectif à l'aide d'une jointure.
SELECT * FROM actors INNER JOIN doctors ON actors.id = doctors.primary_actor - Affichez le titre des serials et leur épisodes avec tous leurs champs à l'aide d'une jointure.
SELECT serials.title AS serial_name, episodes.* FROM serials INNER JOIN episodes ON serials.id = episodes.serial_id - On peut combiner plus de deux tables, il suffit d'ajouter plusieurs INNER JOIN table ON a = b. On va donc pouvoir afficher les saisons et leurs épisodes correspondants. En reprenant la requête précédente, affichez tous les champs de
seasonset tous les champs deepisodescorrespondants à l'aide de deux jointures.SELECT seasons.*, episodes.* FROM serials INNER JOIN episodes ON serials.id = episodes.serial_id INNER JOIN seasons ON serials.season_id = seasons.id - En réutilisant la requête précédente et ce que vous avez vu dans la partie précédente, affichez les noms de saisons et les nombres d'épisodes qu'elles contiennent. Constatez qu'il y avait beaucoup plus de boulot pour regarder une saison entière dans les années 60.
SELECT seasons.name, count(*) FROM serials INNER JOIN episodes ON serials.id = episodes.serial_id INNER JOIN seasons ON serials.season_id = seasons.id GROUP BY seasons.name - Affichez les noms des saisons et les scores d'appréciation moyen par saison triés dans l'ordre décroissant de l'appréciation. Constatez que ma saison préférée est la même que tout le monde.
SELECT seasons.name, avg(episodes.appreciation_index) FROM serials INNER JOIN episodes ON serials.id = episodes.serial_id INNER JOIN seasons ON serials.season_id = seasons.id GROUP BY seasons.name ORDER BY avg(episodes.appreciation_index) DESC - Affichez les noms des saisons, les scores d'appréciation moyen et l'audience moyenne par saison triés dans l'ordre décroissant de l'audience.
SELECT seasons.name, avg(episodes.appreciation_index) , avg(episodes.uk_viewers_mm) FROM serials INNER JOIN episodes ON serials.id = episodes.serial_id INNER JOIN seasons ON serials.season_id = seasons.id GROUP BY seasons.name ORDER BY avg(episodes.uk_viewers_mm) DESC - Question subsidiaire : quel docteur ayant joué dans plus d'1 épisode est le plus apprécié ? (Bon courage !)
SELECT doctors.incarnation, count(episodes.id), avg(episodes.appreciation_index)
FROM serials
INNER JOIN episodes
ON serials.id = episodes.serial_id
INNER JOIN serials_doctors
ON serials.id = serials_doctors.serial_id
INNER JOIN doctors
ON serials_doctors.doctor_id = doctors.id
GROUP BY doctors.incarnation
HAVING count(episodes.id) > 1
ORDER BY avg(episodes.appreciation_index) DESC
LIMIT 1
