Partie 2 : Créer une base de données
Déterminer la structure des données
On l'a vu lors de la dernière séance : dans une base de données, l'information est stockée de manière structurée. Lorsque vous créez une base de données, vous devez donc préalablement déterminer comment structurer les données que vous voulez stocker. Quelles sont les entités qui deviendront les tables, leurs attributs et leurs relations ?
Modèles, entités, attributs, relations
Définitions
En informatique, un modèle de données décrit comment sont représentées des informations dans une base de données ou dans un système d'information. Le modèle de données relationnel que nous avons vu décrit cette représentation à l'aide d'entités, de leurs attributs et de leurs relations.
Une entité est une chose concrète ou abstraite de la réalité perçue à propos de laquelle on veut conserver des informations. Une entité a une existence autonome. Exemple : une personne, un animal, un livre, un produit, une université.
Chaque entité possède des propriétés particulières appelées attributs. Un attribut est une caractéristique ou une qualité d’une entité ou d’une association. Il peut prendre une (ou plusieurs) valeur(s). Exemple : le nom d'un animal, d'une personne.
Les entités sont reliées entre elles par des relations qui peuvent être de plusieurs types :
- Relation de 1 à 1 ou de 0 à 1 : on l'évitera souvent puisqu'elle signifie que les entités peuvent être confondues
- Relation de 1 à n ou 0 à n : par exemple, plusieurs (n) animaux possèdent un type de pelage
- Relation de n à n : par exemple, plusieurs animaux peuvent appartenir à plusieurs personnes
Conventions de nommage
Et oui, comme en programmation, on n'écrit pas n'importe quoi n'importe comment :) On écrit les entités et les attributs au singulier, sans accents, en minuscules et les mots sont séparés par des underscores. Exemple : couleur_pelage.
Concevoir un modèle de données
Plusieurs méthodes de conception existent pour construire un modèle de données relationnel. Ici nous verrons une méthode adaptée de la méthode Merise. On peut aussi utiliser les diagrammes de classes UML (Unified Modeling Language). L'UML est un langage de modélisation utilisé pour normaliser la conception d'un système. Vous l'avez peut être croisé en particulier en programmation orienté objet. Dans les deux cas, Merise ou UML, les concepts sont similaires. Dans la méthode Merise, on parlera d'entités pour désigner le concept que l'on modélise, et en UML de classes. Dans les deux cas toujours, la conception du modèle de données suit deux étapes :
- Un schéma conceptuel des données : il modélise les informations de façon compréhensible pour l'utilisateur qui utilisera la base de données. À cette étape, on considère surtout le sens des informations que l'on structure : quelles sont les entités que je veux modéliser, quelles sont leurs relations ?
- Un schéma logique des données : là on s'attarde sur les aspects techniques. On adapte le schéma aux SGBD utilisés (relationnels), on fait apparaître les clés primaires et étrangères, les types des données. C'est le schéma que je vous ai montré la dernière fois pour la base Doctor Who.
Modèle conceptuel des données
Pour la première étape, on se pose plusieurs questions :
- Quelles sont les entités = les concepts que je veux modéliser ?
- Quels sont leurs attributs = leurs caractéristiques ?
- Quelles sont leurs relations = les liens qui relient les entités ?
Pour schématiser les réponses à ces questions, on écrit le nom de l'entité dans un cadre, et la liste des attributs en dessous. Comme ceci :
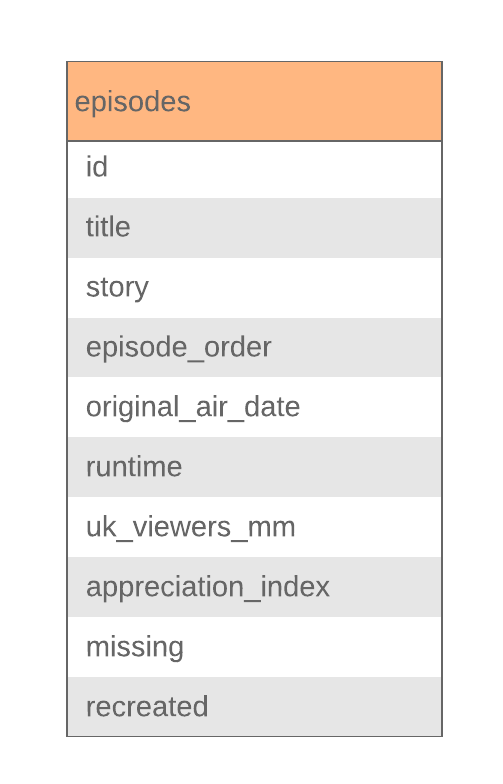
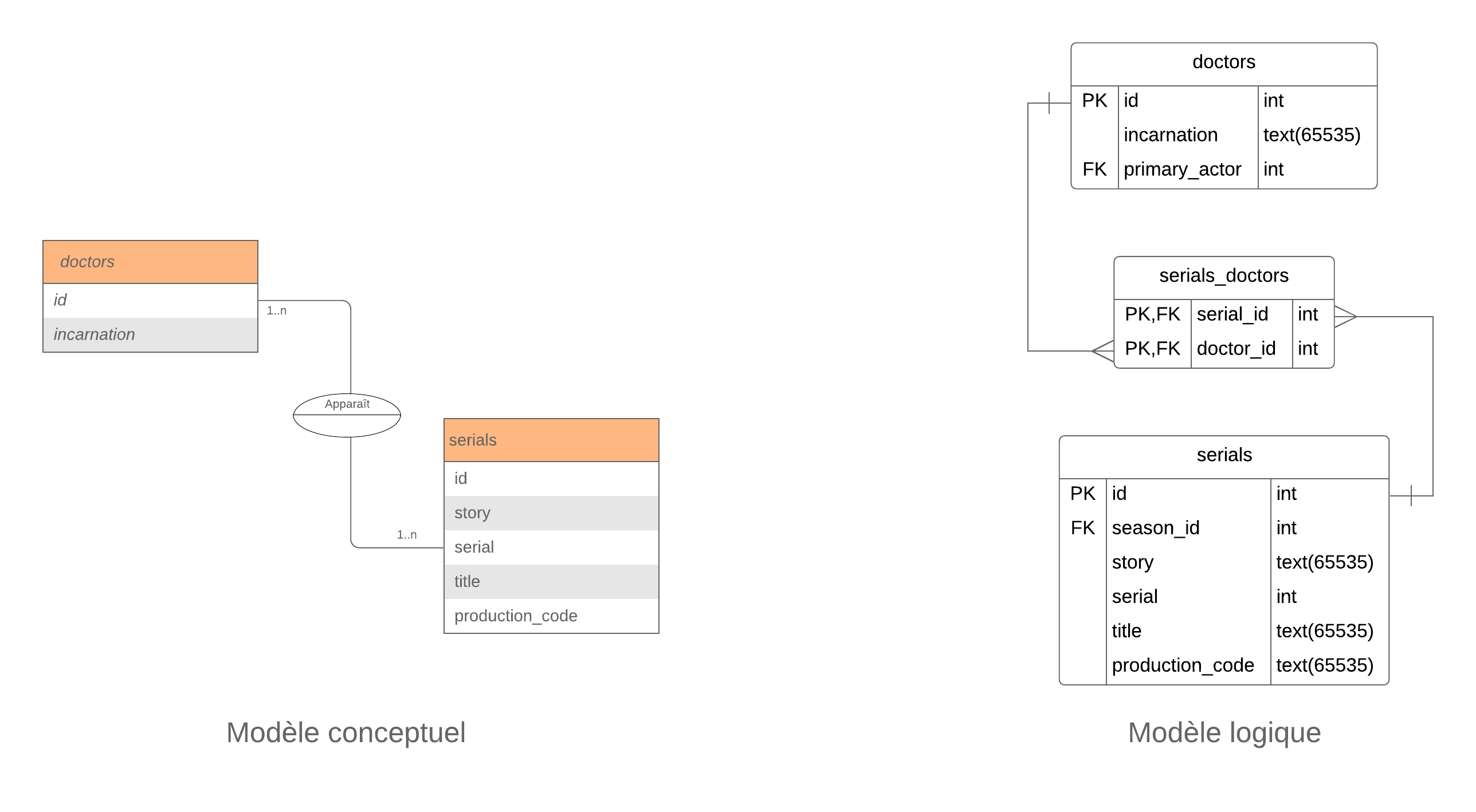
Pour schématiser les relations, on trace des lignes entre les entités et on trace un cercle sur la ligne. Le demi-cercle du haut contiendra l'intitulé de la relation ("a", "possède"..). En général, c'est un verbe ! Le demi-cercle du bas lui contiendra les attributs éventuels de cette relation. On écrit aussi la cardinalité de la relation aux extrémités de la ligne. Par exemple, une saison contient plusieurs serials, la cardinalité est 1..n. Un serial lui est contenu dans une seule saison, la cardinalité est 1..1. Ce sera plus clair en image. Si on reprend nos données de la première séance avec les épisodes de Doctor Who, voici le modèle conceptuel complet :

On retrouve bien toutes nos entités et leurs relations : 1 serial contient plusieurs épisodes etc..
Vous remarquerez qu'à l'issue de cette étape, le schéma représente l'organisation de nos données mais ne nous renseigne pas du tout sur les aspects techniques : les clés ne sont pas représentées et on ne sait pas quels types seront utilisés pour stocker les valeurs des attributs. C'est l'objectif de l'étape suivante, mais avant, exercice !
Je vous propose de continuer dans les sujets pas sérieux, on aura le temps de faire du sérieux en éval et en stage. Cherchons donc un modèle conceptuel des données pour gérer les jeux Nintendo (parce que Zelda.). Il faudra gérer 3 entités : les consoles, les jeux vidéos et les développeurs des jeux. Pour les jeux vidéo, vous aurez besoin plus tard dans le TP de connaître leur prix à la sortie et leur date de sortie. Et je n'en dis pas plus, cherchez les attributs qu'il sera utile de stocker, les relations entre les entités, à vous de jouer ! Vous pouvez ajouter des entités si ça vous semble nécessaire. N'hésitez pas à réfléchir à plusieurs, à aller gribouiller au tableau, c'est souvent bien utile à cette étape.
Si vous voulez faire de jolis schémas, vous pouvez utiliser LucidChart (inscription nécessaire, gratuit pour les comptes Basic) ou Draw.io (Gratuit, pas d'inscription nécessaire). Si vous voulez reprendre mon schéma du dessus, vous pouvez le trouver ici sur LucidChart. Vous cliquez ensuite sur File puis New Document et vous pourrez créer une copie à partir de laquelle travailler. Papier crayon sont tout à fait possibles aussi (peut-être mieux pour réfléchir ?)
Modèle logique des données
Maintenant il est temps de se pencher sur la façon selon laquelle nos données seront représentées dans notre base de données. C'est le but du modèle logique. Il nous renseignera sur les clés primaires et étrangères, les types utilisés. Bref, il permet d'implémenter le modèle dans un SGBD donné.
Pour passer du modèle conceptuel au modèle logique, on se consacre surtout à la notation des relations. Les cercles avec l'intitulé de la relation disparaissent au profit de la clé étrangère. Exemple avec nos tables seasons et serials :

Notez les extrémités de la flèche dans le modèle logique : la barre signifie 1, la fourchette signifie plusieurs. C'est la notation dite en patte de corbeau.
Cas des relations n à n
Si de chaque côté de la relation, la cardinalité est de 0..n ou 1..n, on a donc une relation de type n à n. C'est le cas de notre relation "Apparaît" entre les entités doctors et serials. Dans ce cas particulier, on doit créer une table intermédiaire qui contiendra les clés de chaque entité : c'est notre table serials_doctors.
Si on applique ceci à toutes les entités, on obtient notre schéma complet, avec toutes les clés primaires et étrangères indiquées :
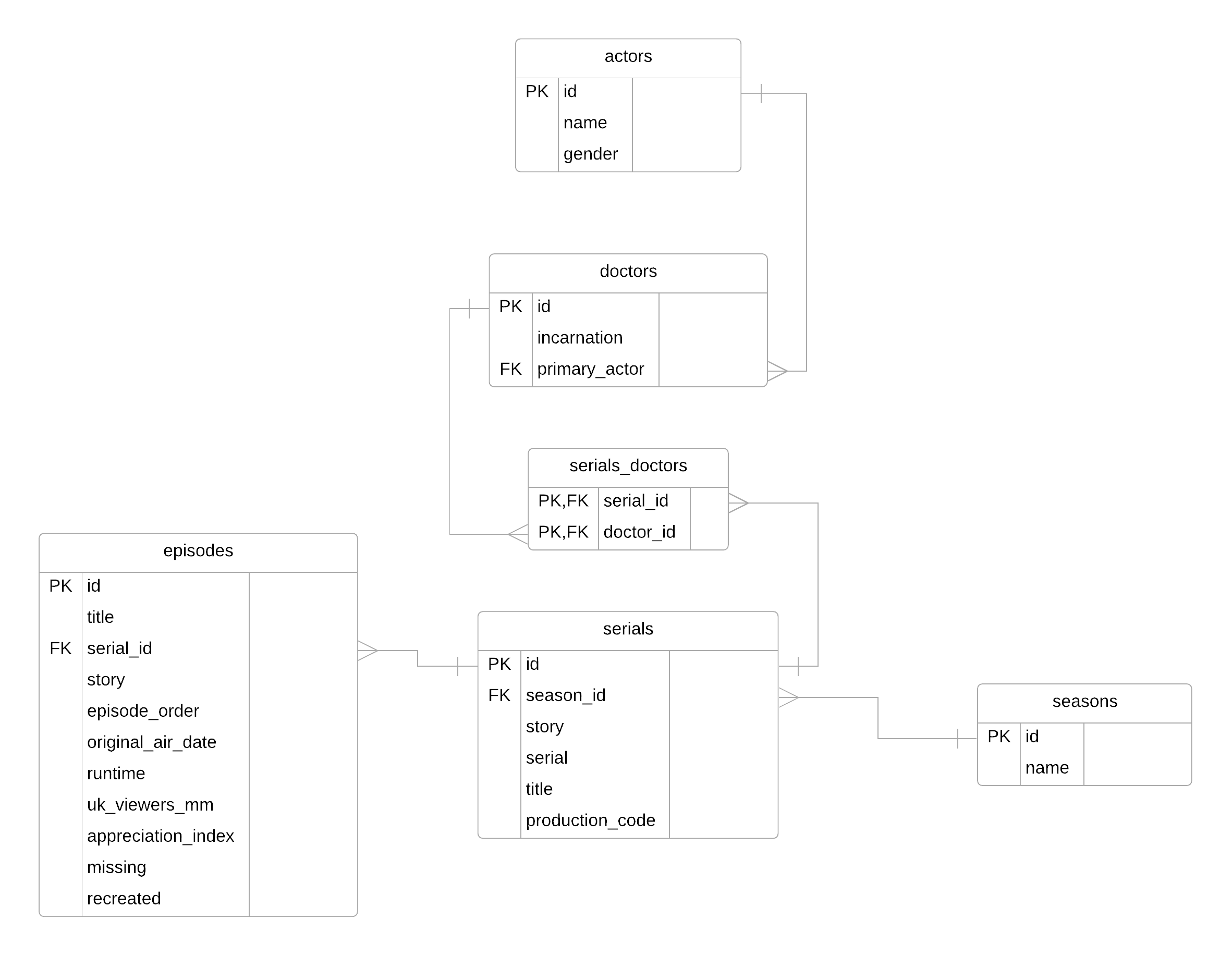
Une fois toutes les relations transcrites dans le modèle logique et les clés étrangères insérées, on doit encore indiquer les types des attributs dans le modèle. Et donc savoir les choisir !
Choisir les types de données
Rassurez-vous, on en a fini avec les 1 et les n. On va voir les différents types de données, numériques, temporels et textuels.
Il en existe un certain nombre (un nombre certain même) et il peut être difficile de savoir lequel utiliser. C'est pourtant un aspect important : choisir un type inadapté pourra entrainer des performances moindres de la base de données, un gaspillage des ressources en mémoire, voire des dysfonctionnements (un tri sur une chaîne de caractères au lieu d'un nombre peut donner des résultats originaux !).
Types de données numériques
Comme en programmation, on a des types entiers et des types décimaux. Jusque là rien d'original. Les voici.
Types entiers
| Type | Nombre d'octets occupés | Valeur minimum | Valeur maximum |
|---|---|---|---|
TINYINT |
1 | -128 | 127 |
SMALLINT | 2 | -32768 | 32767 |
MEDIUMINT | 3 | -8388608 | 8388607 |
INT | 4 | -2147483648 | 2147483647 |
BIGINT | 8 | -263 | 263-1 |
Note : quand vous voyez écrit INT(5), le 5 ne désigne pas la place occupée. Un INT occupe toujours 4 octets. Le 5 désigne le nombre de chiffres affichés par défaut, en insérant des espaces ou des zéros (avec l'option ZEROFILL) pour arriver à 5 caractères.
Note #2 : on peut utiliser des types non signés avec l'option UNSIGNED pour stocker des nombres que l'on sait toujours positifs. Dans ce cas, la valeur minimale de la colonne sera 0 et la valeur maximum sera celle du type signé multipliée par 2 + 1.
Note #3 : Les types BOOL ou BOOLEAN peuvent être utilisés pour stocker des valeurs booléennes. Ce sont des synonymes pour TINYINT(1). La valeur 0 sera considérée fausse, toutes les autres valeurs positives seront considérées vraies.
Il est donc important de choisir le type adapté aux nombres que vous souhaitez stocker. Si vous choisissez un BIGINT pour stocker une valeur booléenne ou un pourcentage de 0 à 100, vous réserverez de l'espace mémoire pour rien. Au contraire, si vous choisissez un TINYINT pour stocker un prix, vous ne pourrez pas stocker de valeur supérieure à 127 (255 si UNSIGNED). Ça risque de poser problème si vous vendez des télés... Sans comptez que pour un prix, vous devriez avoir besoin de décimales !
Types décimaux
Les types décimaux acceptent deux paramètres :
- La précision M : le nombre de chiffres significatifs total du nombre
- L'échelle D : le nombre de chiffres après la virgule
Voici les différents types et leurs synonymes (nombreux, pour des questions de compatibilité entre SGBD).
| Type et synonymes | Nombre d'octets occupés | Précision M maximale | Précision M par défaut | Échelle D maximale | Échelle D par défaut |
|---|---|---|---|---|---|
DECIMAL(M,D)DEC(M,D)NUMERIC(M,D)FIXED(M,D) | varie | 65 | 10 | 30 | 0 |
FLOAT(M,D) | 4 | 24 | 24 | 7 | 7 |
DOUBLE(M,D)DOUBLE PRECISION(M,D)REAL(M,D) | 8 | 53 | 53 | 15 | 15 |
Exemple : si on déclare le type DECIMAL(8,2), on pourra stocker des nombres comportant au maximum 8 chiffres, dont 2 après la virgule, soit au maximum 999 999.99 (6 avant la virgule, 2 après, 8 au total). Pour des prix, ça semble pas mal.
Il existe une grosse différence entre le type DECIMAL et les types FLOAT/DOUBLE : le type DECIMAL permet de stocker la valeur exacte. Par exemple, si vous voulez stocker 1099.99 (un prix), les types FLOAT et DOUBLE stockeront une valeur approchée. Ça pourra être 1099.99999901 par exemple. Le type DECIMAL lui stockera la valeur exacte. De manière générale, on utilisera donc les valeurs flottantes pour des nombres destinés à des calculs. Pour les valeurs financières/monétaires, utilisez DECIMAL.
Types de données textuels
Plusieurs types existent pour stocker du texte :
CHAR(n)permet de stocker exactement n caractèresVARCHAR(n)permet de stocker une chaîne de longueur variable entre 0 et n caractères. La longueur occupée en mémoire variera en fonction de la longueur de la chaîne de caractères.TINYTEXT,TEXT,MEDIUMTEXTetLONGTEXTqui permettront de stocker des textes dont la longueur est trop importante pour le typeVARCHAR
Voici leurs caractéristiques :
| Type | Longueur max | Mémoire occupée |
|---|---|---|
CHAR | 255 caractères | Longueur de la chaîne octets |
VARCHAR | 65 535 caractères | Longueur de la chaîne + 1 octet si longueur inférieure à 255, + 2 octets sinon |
TINYTEXT | 255 caractères | Longueur de la chaîne + 1 octet |
TEXT | 65 535 caractères | Longueur de la chaîne + 2 octets |
MEDIUMTEXT | 224 -1 caractères | Longueur de la chaîne + 3 octets |
LONGTEXT | 232 -1 caractères | Longueur de la chaîne + 4 octets |
Ainsi, CHAR(5) permet de stocker exactement 5 caractères tandis que VARCHAR(5) permet d'en stocker jusqu'à 5. La différence ? La mémoire occupée. VARCHAR utilise un préfixe supplémentaire qui occupe 1 octet de plus par valeur. Si on veut stocker un code postal par exemple qui fera toujours 5 caractères, CHAR(5) est le plus efficace.
Attention, dans tous les cas, la longueur maximale de la chaîne dépendra de l'encodage utilisé. En UTF-8, la lettre "a" occupe un octet, la lettre "é" en occupe 2. On ne pourra donc stocker au maximum que 32 767 "é" dans un champ TEXT !
D'autres types existent sur lesquels on ne s'attardera pas :
- Les types binaires :
BINARY,VARBINARYetBLOBet dérivés (TINYBLOBetc.) : ils fonctionnent comme leurs équivalents pour le texte mais servent à stocker des chaînes binaires. - Les énumérations
ENUMetSET: elles servent à stocker des listes de valeurs possibles pour une colonne. Ça semble pratique dis comme ça mais ne les utilisez pas. Elles sont propres à MySQL et vous empêcheraient de transférer votre base de données sur tout autre SGBD. Préférez utiliser des tables pour stocker ces valeurs.
Types de données temporels
Ah les dates... Des types spéciaux existent pour les gérer. Rassurez-vous, ils sont moins nombreux :
DATE: une date au format 'YYYY-MM-DD' de '1000-01-01' à '9999-12-31'DATETIME: une date et heure au format YYYY-MM-DD HH:MM:SS[.fraction] de '1000-01-01 00:00:00.000000' à '9999-12-31 23:59:59.999999'TIMESTAMP: le temps écoulé depuis le 1 janvier 1970 à minuit, de '1970-01-01 00:00:01.000000' UTC à '2038-01-19 03:14:07.999999' UTC.TIME: un temps au format 'HH:MM:SS[.fraction]' de '-838:59:59.000000' à '838:59:59.000000'YEAR: une année, sur 4 caractères de 1901 à 2155
Attention, les fonctions AVG et SUM ne fonctionnent pas avec ces types (la conversion échoue dès qu'un caractère non numérique est rencontré).
Voilà, respirez c'est fini. On peut maintenant compléter le schéma logique des données de notre base doctorwho :
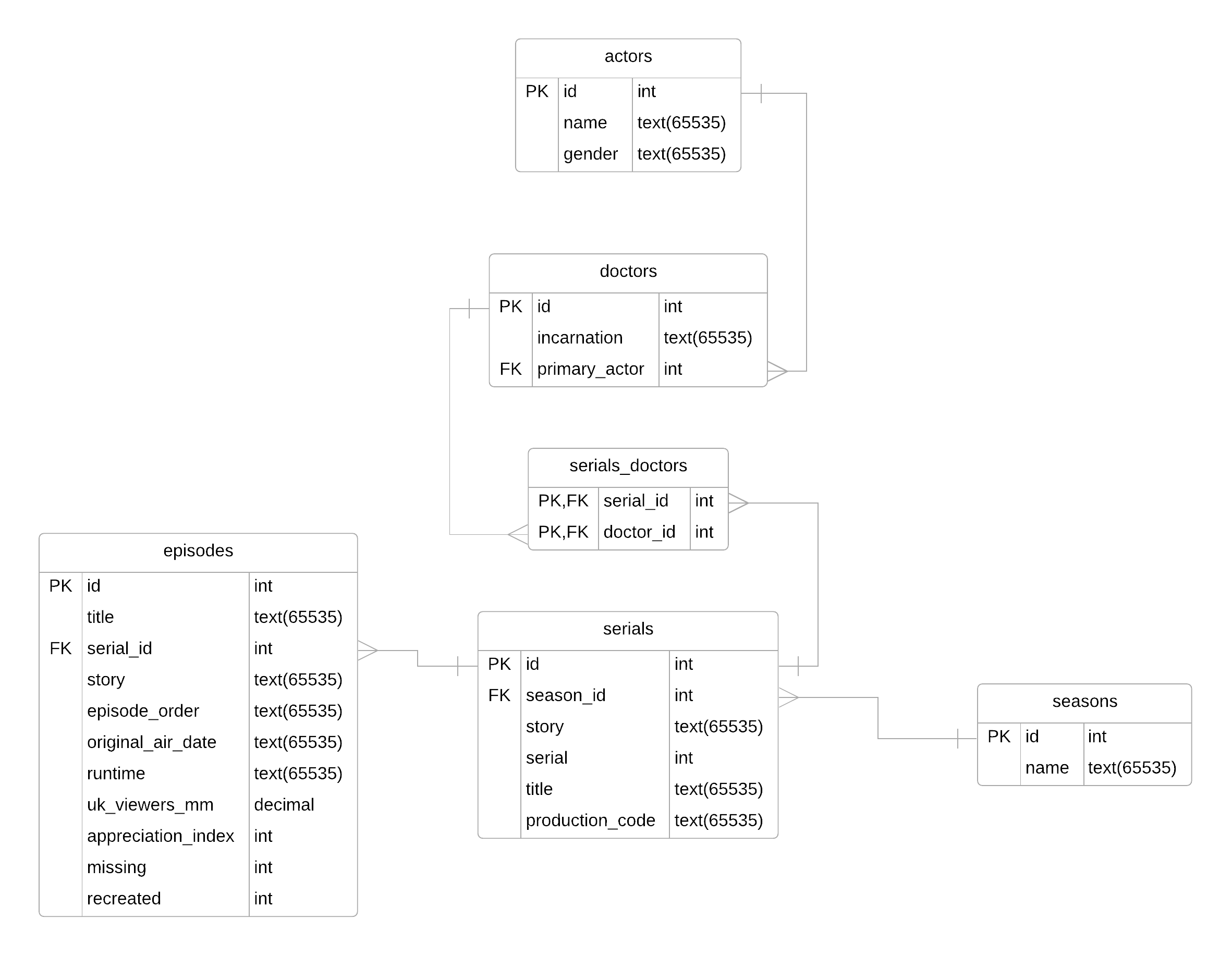
Comme vous pouvez le voir, dans cette base, on utilise souvent les mêmes types. La raison est simple : la base a été publiée sur Github (version complète ici), je n'ai donc pas choisi les types moi-même et j'imagine que l'auteur a privilégié la compatibilité. En effet, avec SQLite en particulier, seuls les types NULL, INTEGER, REAL, TEXT et BLOB sont disponibles.
Je vous propose donc de reprendre ce schéma et de modifier les types des colonnes pour les remplacer par ceux qui vous semblent les plus appropriés parmi les types que nous venons de voir.
Même chose, n'hésitez pas à en discuter entre vous.
Reprenez votre schéma conceptuel des données que vous avez réalisé dans l'exercice 1 pour les jeux Nintendo et établissez le modèle logique : créez les clés et choisissez les types appropriés.

Créer la base de données en SQL
La partie difficile est terminée. Lorsqu'on connaît le modèle de données, créer la base en SQL n'est plus qu'une formalité. Nous allons voir les instructions en SQL qui permettent de créer la base et les tables.
Créer la base en elle-même
Pour créer une base de données, on utilise l'instruction CREATE DATABASE, comme ceci :
CREATE DATABASE nom_base;
Par défaut dans MySQL, l'encodage utilise est l'UTF-8. Si vous vouliez le changer (je ne le conseille pas...), on ajoute (vous l'avez vu la semaine dernière ! ) :
CREATE DATABASE nom_base CHARACTER SET 'utf8';
Pour ensuite utiliser la base de données, simplement :
USE nom_base;
Et pour la supprimer (attention quand même, vous supprimerez toutes les données de la base !) :
DROP DATABASE nom_base;
Toutes ces actions sont accessibles via l'interface de PhpMyAdmin mais elles sont bien utiles à connaître pour exporter une base !
Créer les tables
La base créée, reste à s'occuper des tables, c'est la partie qui prend le plus de temps.
Créer une table
CREATE TABLE
L'instruction qui permet de créer une table est CREATE TABLE. Elle suit cette syntaxe :
CREATE TABLE nom_table (
colonne1 description,
colonne2 description,
...,
[PRIMARY KEY (colonne_clé_primaire)]
);
colonne1, colonne2 sont les noms des colonnes, la description contiendra le type de la colonne et certaines options. On précise quelle colonne représente la clé primaire à la fin. Exemple avec notre table serials :
CREATE TABLE `serials` (
`id` INT(11),
`season_id` INT(11),
`story` TEXT,
`serial` INT(11),
`title` TEXT,
`production_code` TEXT,
PRIMARY KEY (`id`)
);
Valeurs non nulles
La description des colonnes peut indiquer que les valeurs de la colonne ne peuvent pas être nulles. Chaque enregistrement devra donc comporter obligatoirement une valeur pour cette colonne. C'est obligatoirement le cas des clés primaires. On écrit alors NOT NULL dans la description de la colonne.
Valeurs par défaut
La description des colonnes peut aussi indiquer une valeur par défaut pour une colonne. Souvent on utilisera DEFAULT NULL. Si aucune valeur n'est indiquée, ce sera donc NULL qui sera utilisé.
Auto-incrémentation
Pour les clés primaires, il est bien pratique d'indiquer que le moteur de base de données doit assigner automatiquement la valeur de l'identifiant, en l'augmentant de 1 pour chaque nouvelle ligne. On l'indique avec le mot-clé AUTO_INCREMENT.
CREATE TABLE `serials` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`season_id` INT(11) NOT NULL,
`story` TEXT,
`serial` INT(11) DEFAULT NULL,
`title` TEXT NOT NULL DEFAULT "Un super titre",
`production_code` TEXT,
PRIMARY KEY (`id`)
);
Les index
Les index sont utilisés pour trouver des lignes possédant des valeurs particulières rapidement. Sans index, le moteur de base de données doit chercher à partir de la première ligne de la table et la parcourir pour trouver les lignes correspondantes à la requête. Plus la table est grande, plus l'opération est couteuse bien sûr. Si la table possède un index sur la colonne sur laquelle la recherche s'effectue, le moteur pour déterminer la position à chercher parmi les données beaucoup plus rapidement, sans avoir à parcourir toute la table. C'est donc beaucoup plus rapide que de lire toutes les lignes une à une.
Techniquement, les index sont stockés dans des structures de données appelées arbres B : ce sont des structures en arbre où les données sont triées. Vous n'avez pas besoin d'en savoir plus (mais vous pouvez lire la doc si ça vous intéresse), c'est le moteur de base de données qui s'occupe de les gérer.
De votre côté, votre rôle est de déterminer quelles colonnes il sera intéressant d'indexer. Ce sont les colonnes dans lesquelles vous rechercherez souvent des informations : un nom ou un titre par exemple.
Le moteur InnoDB utilisé par défaut dans MySQL supporte 3 types d'index :
PRIMARY KEY: votre clé primaire est un index !UNIQUE: une colonne où toutes les valeurs seront uniques. La différence avec une clé primaire c'est que la colonne peut contenir des valeursNULL.KEYouINDEX: les deux sont synonymes. C'est une colonne gérant des valeurs de toute sorte, non unique, et qui peuvent être nulles.
Pour les déclarer, vous pouvez les ajouter à la fin comme on l'a fait pour la clé primaire tout à l'heure :
CREATE TABLE imaginaire (
id INT AUTO_INCREMENT,
colonne1 SMALLINT,
colonne2 VARCHAR(255),
PRIMARY KEY (id),
UNIQUE (colonne1),
KEY (colonne2)
);
Modifier une table
Pour modifier une table, on utilise l'instruction ALTER TABLE.
Ajouter une colonne
ALTER TABLE imaginaire
ADD colonne3 description;
Supprimer une colonne
ALTER TABLE imaginaire
DROP colonne3;
Modifier une colonne
Pour modifier une colonne, vous avez deux mots-clés : CHANGE permet de modifier le nom de la colonne et sa description tandis que MODIFY ne permet que de changer la description.
ALTER TABLE imaginaire
CHANGE colonne1 nouveau_nom nouvelle_description;
ALTER TABLE imaginaire
MODIFY colonne2 nouvelle_description;
Quand vous modifiez la description d'une colonne, vous devez à nouveau précisez toutes les options (NOT NULL), l'ancienne description est totalement écrasée.
Vous pouvez de la même facon ajouter ou supprimer une clé primaire ou un index à une table après sa création :
ALTER TABLE imaginaire
ADD INDEX (colonne3);
Les contraintes
On a déjà vu les contraintes en réalité ! Les contraintes permettent de contrôler les données d'une table :
- Contraintes d'unicité : avec les clés primaires et les index uniques
- Contraintes de valeur par défaut avec
DEFAULT - Contraintes de valeur non nulle avec
NOT NULL - Contraintes de validation avec
CHECK, elles ne sont pas implémentées dans MySQL donc je n'en parlerai pas. Sachez juste qu'elles permettent de définir une contrainte complexe, par exemple que la longueur d'un champ texte est supérieure à 10/
Les contraintes que nous n'avons pas encore vues sont les contraintes d'intégrité : celles qui concernent les liens entre les tables, les fameuses clés étrangères. Elles permettent de s'assurer que les liens entre les tables sont maintenus quelque soit les modifications engendrées sur les données dans l'une ou l'autre table. On les déclare avec la clause FOREIGN KEY.
Dans notre base doctorwho par exemple, il existe plusieurs clés étrangères, notamment celle entre une saison et un serial. Elle assure qu'on ne pourra pas insérer un serial qui référence une saison qui n'existe pas ! Si vous essayez, vous aurez un message d'erreur vous signalant que vous violez une contrainte d'intégrité.
Au niveau de la syntaxe, il nous faudra indiquer plusieurs informations :
- le nom de la contrainte,
season_id_fkdans notre exemple - le nom de la colonne de la clé étrangère dans la table :
season_id - le nom de la colonne qu'elle référence :
`seasons` (`id`), la colonne id dans la table seasons
ALTER TABLE `serials`
ADD CONSTRAINT `season_id_fk` FOREIGN KEY (`season_id`) REFERENCES `seasons` (`id`);
Options des clés étrangères
Question : que va t'il se passer si je supprime une saison de ma table seasons ? Et bien par défaut, MySQL vous en empêchera si des références à cette saison existent dans la base de données. C'est l'objet même de la contrainte d'intégrité. Concrètement, ça veut dire que par défaut vous devrez d'abord supprimer tous les serial d'une saison avant de pouvoir supprimer la dite saison. Il existe des options pour contrôler ce comportement.
Pour contrôler le comportement adopté lors d'une suppression, on utilise l'option ON DELETE. Pour le comportement adopté lors de la modification, c'est l'option ON UPDATE. Ces deux options proposent 3 choix :
RESTRICTouNO ACTION: c'est le comportement par défaut : une valeur référencée ne pourra pas être supprimée ou modifiéeSET NULL: si on supprime ou modifie une saison, alors les références à cette saison prendront la valeurNULL.CASCADE: si on supprime une saison alors toutes les références à cette saison seront également supprimées. Concrètement, en supprimant une saison, on supprimera également tous ses serials. À manipuler avec précaution donc. Si on modifie la saison, sa référence sera également modifiée.
Voici un exemple avec notre table avec les valeurs par défaut :
ALTER TABLE `serials`
ADD CONSTRAINT `season_id_fk` FOREIGN KEY (`season_id`) REFERENCES `seasons` (`id`) ON DELETE RESTRICT ON UPDATE RESTRICT;
Reprenez votre schéma logique des données que vous avez réalisé dans l'exercice 3 pour les jeux Nintendo et écrivez les instructions SQL permettant de créer la base et ses tables.
Exécutez vos requêtes dans PhpMyAdmin et vérifiez qu'elles sont correctes et que la base est correctement créée.
Insérer, mettre à jour, supprimer des données
Insérer des données en SQL
Pour insérer des données dans une table, on utilise l'instruction INSERT.
INSERT INTO `serials` (`id`, `season_id`, `story`, `serial`, `title`, `production_code`) VALUES
(1, 1, '1', 1, 'An Unearthly Child', 'A');
Attention à bien utiliser des guillemets autour des champs texte.
On n'est pas obligé d'indiquer toutes les colonnes. En particulier, si le champ id est auto-incrémenté, il suffit de faire :
INSERT INTO `serials` (`season_id`, `story`, `serial`, `title`, `production_code`) VALUES
(1, '1', 1, 'An Unearthly Child', 'A');
Le champ id sera calculé automatiquement par le moteur.
On peut ne pas indiquer le nom des colonnes, mais il faudra alors indiquer des valeurs pour toutes les colonnes :
INSERT INTO `serials` VALUES
(1, 1, '1', 1, 'An Unearthly Child', 'A');
Pour finir, vous pouvez insérer plusieurs lignes à l'aide d'une seule instruction, comme ceci :
INSERT INTO `serials` (`id`, `season_id`, `story`, `serial`, `title`, `production_code`) VALUES
(1, 1, '1', 1, 'An Unearthly Child', 'A'),
(2, 1, '2', 2, 'The Daleks', 'B'),
(3, 1, '3', 3, 'The Edge of Destruction', 'C'),
(4, 1, '4', 4, 'Marco Polo', 'D'),
...
;
Mettre à jour des données en SQL
Pour modifier des enregistrements, on utilise l'instruction UPDATE. Pour modifier le titre du serial ayant l'id 1 par exemple, sa syntaxe est :
UPDATE serial
set title='Le nouveau titre'
WHERE id=1;
On peut très bien modifier plusieurs colonnes à la fois :
UPDATE serial
set title='Le nouveau titre', production_code='ADG'
WHERE id=1;
Supprimer des données en SQL
Pour supprimer des enregistrements, on utilise l'instruction DELETE. Pour supprimer le serial ayant l'id 1 par exemple, sa syntaxe est :
DELETE FROM serial
WHERE id=1;
Pour supprimer toutes les lignes de la table :
DELETE FROM serial;
Écrivez des commandes inserts pour ajouter des données à votre base nintendo :
- Au moins 2 développeurs dont Nintendo EAD
- Au moins 2 consoles dont la Switch
- Au moins 6 jeux vidéos dont au moins 1 est présent sur les deux consoles
Exécutez vos requêtes dans PhpMyAdmin et vérifiez qu'elles sont correctes et que les données ont été correctement insérées.
Vous pouvez vous aider de cette page qui répertorie les jeux Switch et celle-ci pour la GameCube par exemple.
Exporter une base ou des données
PhpMyAdmin permet via son interface d'exporter vos bases de données. C'est bien pratique pour sauvegarder votre base, ou la partager avec un collègue. Vous pourrez voir ces sauvegardes appelées également `dump`. Pour exporter votre base, vous devrez sélectionnez la base de données à sauvegarder dans le menu à gauche puis aller dans l'onglet Exporter. Le format à sélectionner est SQL. De multiples options sont disponibles, à choisir au cas par cas.
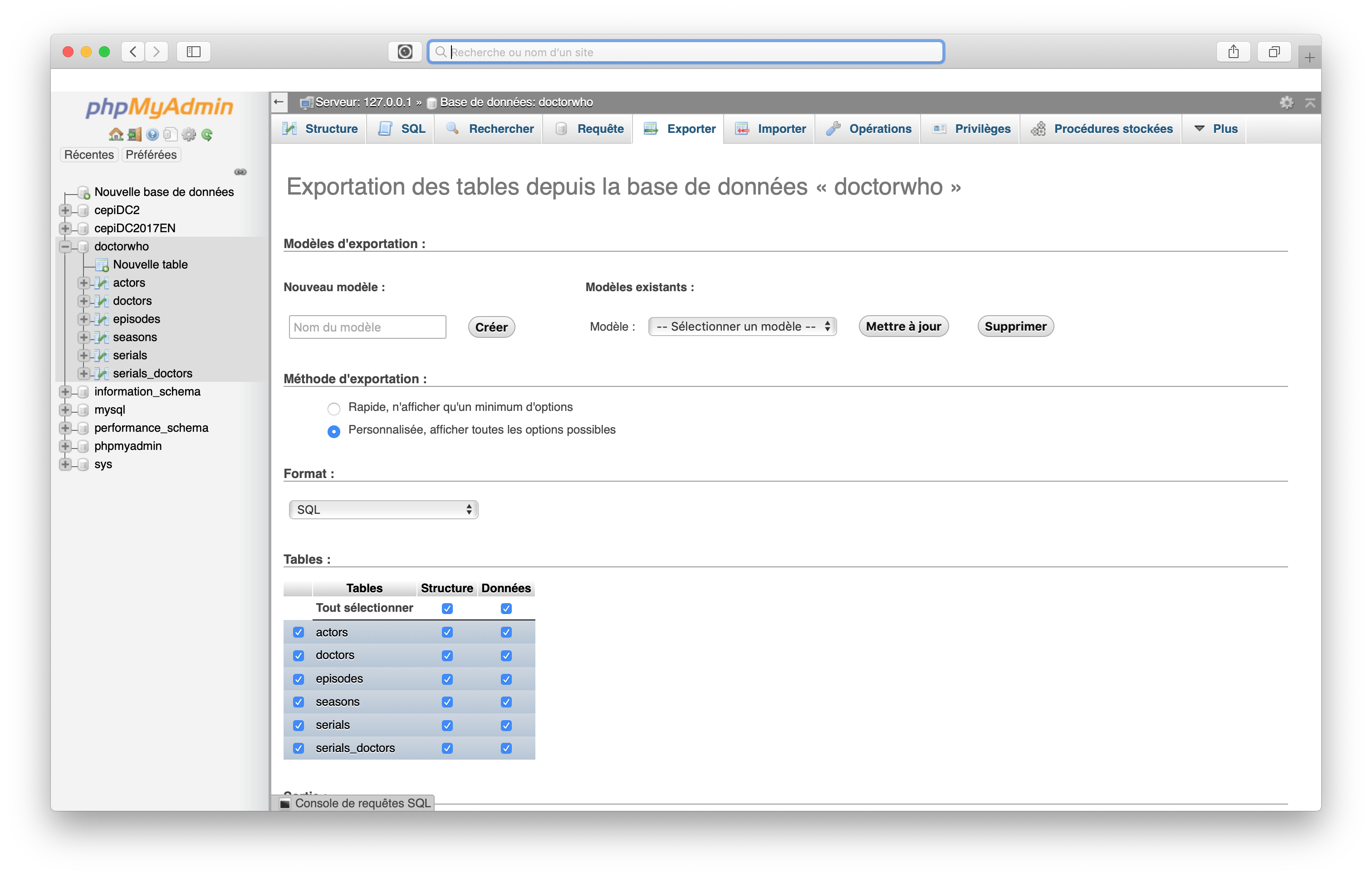
Vous pouvez également exporter les résultats d'une requête : pour les communiquer à un collègue, en construire des graphes etc. Voyez sur cette capture :
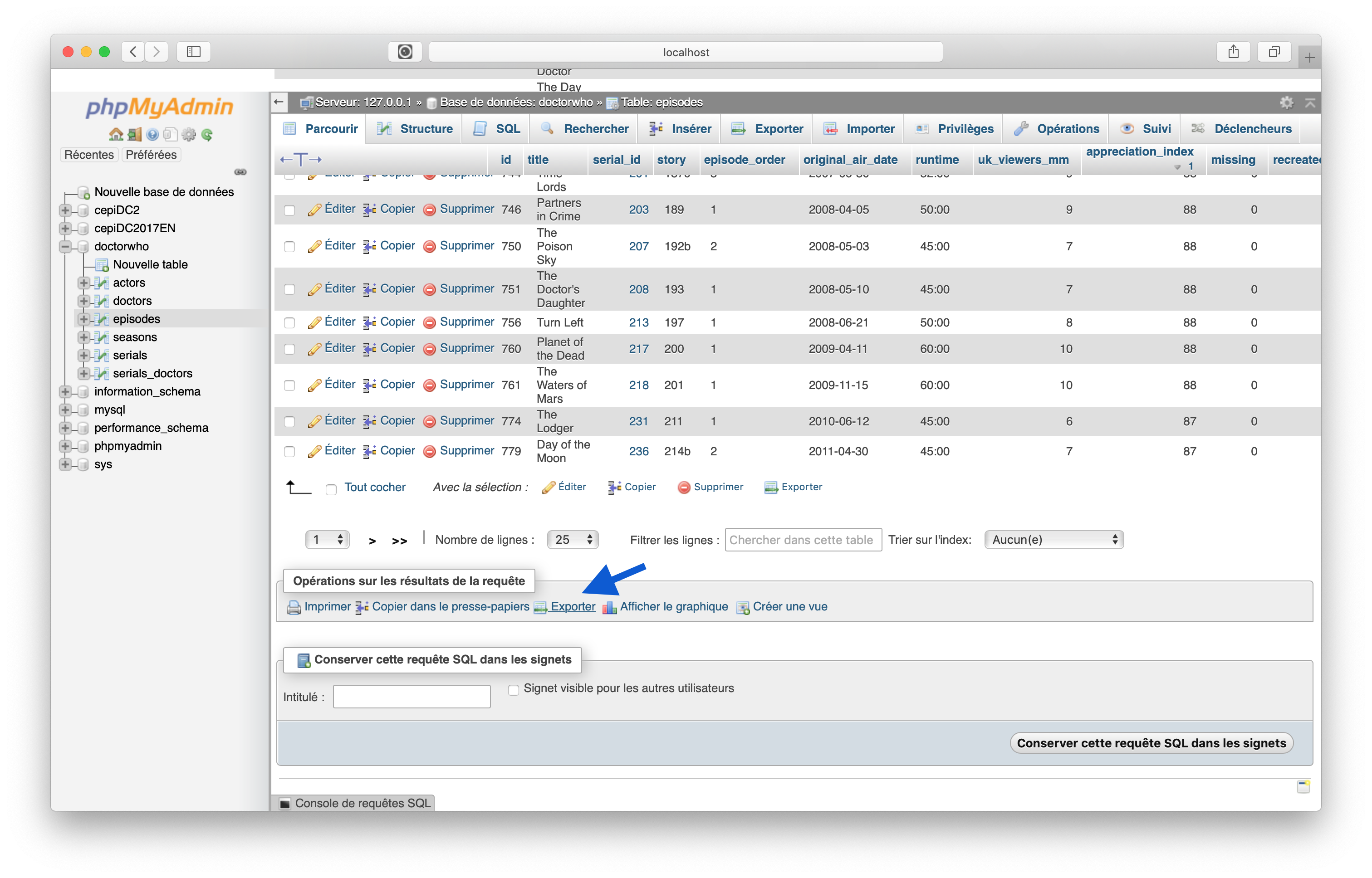
Vous devrez alors choisir votre format. Couramment on choisira le CSV.
- Faîtes tout d'abord une sauvegarde complète de votre base de données au format SQL en un fichier unique.
- Ouvrez ce fichier SQL et parcourez-le, vous reconnaitrez les instructions que nous avons vues dans la partie 2. Assurez-vous que tout est correct.
- Supprimez votre base de données et réimportez-la à partir de votre sauvegarde.
On va réviser quelques une des requêtes vues lors de la première séance.
- Sélectionnez tous les jeux qui commencent par "T".
SELECT * FROM `game` WHERE name LIKE "T%"; - Sélectionnez le prix moyen des jeux à leur sortie
SELECT AVG(original_price) FROM game; - Sélectionnez tous les jeux de la Switch
SELECT game.* FROM `game` INNER JOIN game_platform ON game.id = game_platform.game_id INNER JOIN platform ON game_platform.platform_id=platform.id WHERE platform.name="Switch" - Affichez le nombre de jeux par console
SELECT platform.name, COUNT(game.id) FROM `game` INNER JOIN game_platform ON game.id = game_platform.game_id INNER JOIN platform ON game_platform.platform_id=platform.id GROUP BY (platform.name) - Affichez tous les jeux de la Switch développés par Nintendo triés par date de sortie décroissante. Exportez les résultats au format CSV.
SELECT game.* FROM `game` INNER JOIN game_platform ON game.id = game_platform.game_id INNER JOIN platform ON game_platform.platform_id=platform.id INNER JOIN company_game ON company_game.game_id = game.id INNER JOIN company ON company.id = company_game.company_id WHERE platform.name="Switch" and company.name LIKE "%Nintendo%" ORDER BY game.release_date_EU DESC;